

What Are The Risks With Machine Learning For Url Categorization
Malicious webpage classification using machine learning
Introduction
ML based applications has been on the rise for a long time, we see its usages on almost all areas, let it be predicting scores, recommender systems, stock markets and list goes on forever. Nosotros use Machine learning to classify webpages whether they are malicious or non also. This helps in making us aware about the websites and we tin besides save our information from getting stolen. Hereby in the next section, I explain the algorithm and code used for webpage classification.
Code explanation
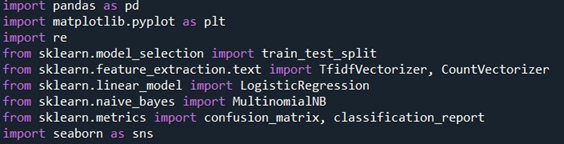
This cake of code imports the necesTsary libraries and functionalities required for preprocessing of our dataset and predicting the webpage URLs as whether they are malicious or non.
· Pandas- Pandas is required for loading the dataset from its directory, for necessary preprocessing and segregating the test data, railroad train information and test labels.
· Matplotlib — Matplotlib is required for data visualization, to understand the interesting trends underlying within the data and to make process them accordingly.
· re- re is short-hand notation of Regular expression, which we use it during the preprocessing of our dataset to remove stop words, dots, 'www' & etc.
· Train_test_split- We import this for splitting our data into proper proportionate of examination and train data. The about encouraged proportion of test and train data is 20% and 80% respectively.
· TFIDFVectorizer-TF-IDF is an abbreviation for Term Frequency Changed Document Frequency. This is very common algorithm to transform text into a meaningful representation of numbers which is used to fit car algorithm for prediction.
· CountVectorizer — Used to convert a collection of text documents to a vector of term/token counts. Information technology also enables the pre-processing of text information prior to generating the vector representation.
· LogisticRegression, MultinomialNB- Pre-trained ML libraries which will exist used for predicting whether the webpage is malicious or not.
Confusion Matrix, Classification report- We apply this to sympathise the operation of our ML algorithm over the dataset, and necessary amendments to improve its functioning
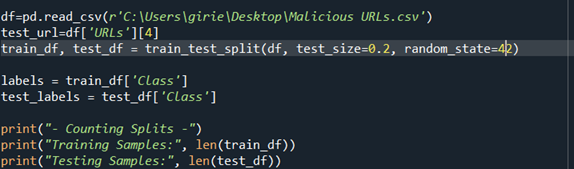
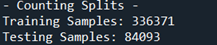
This cake of code loads the dataset from the directory. Then we assign a particular information of dataset 'URLs' as a test url to look how well the preprocessing is done. In subsequent line we import train_test_split of Sklearn library to divide the data set into lxxx% of train and twenty% of test dataset. We assign the variable 'labels' to 'class' cavalcade of train data, while we assign 'test_labels' to grade cavalcade of examination information. So we print the no of Train data samples and exam information samples in the console like this:
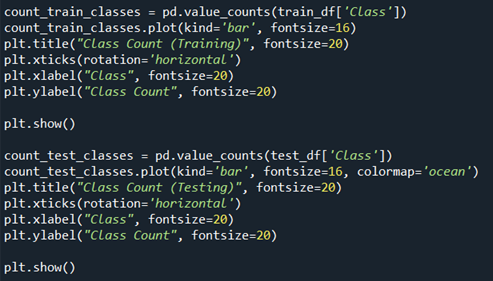
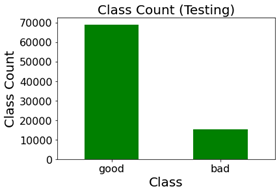
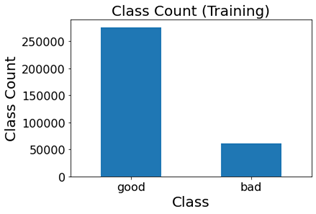
This block of lawmaking is for visualizing the no of skillful and bad urls in both train information and test data respectively. We employ pandas functionalities to count the no of expert and bad urls. The upper portion of block does the counting of expert and bad url in train data, while the below portion of cake does the counting of good and bad url for the test data. The counting procedure is carried over by 'pd.value_counts'. Using '.plot' we depict the count of good and bad urls in form of bar graph. Then we specify sure parameters such every bit fontsize, rotation to give the heading of bar graph a certain size, we specify the graph to exist in form of bar graph using the parameter 'kind=bar'. Nosotros do the aforementioned for test data likewise. This the representation we get:

We ascertain a function for carrying out the necessary preprocessing of the text present in URL.
· tokens = re.split('[/-]', url)
This line of lawmaking splits the url whenever in that location is a '/' or '-'. Next upon we have a
for-loop that iterates over each and every urls in the data
· if i.find(".") >= 0: dot_split = i.split('.')
This line of code checks for dots in the url, if found it splits the url into two pieces at that instant namely into, domain and extension.
· if "com" in dot_split:
dot_split.remove("com")
if "world wide web" in dot_split:
dot_split.remove("www")
This cake removes the extensions such every bit 'www' and 'com' in the pre-candy urls to return only the proper name of the webpage as they don't add whatever context.
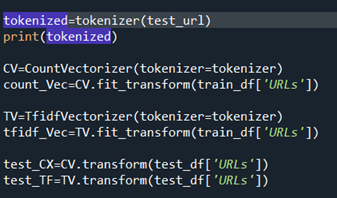
To exam how well the preprocessing is done over the dataset nosotros call in the role nosotros divers in our final block to preprocess one of the test urls we already declared at afterward stage. Nosotros innovate a functionality called CountVectorizer and TFIDF vectorizer. Tokenization is the process of removing stop words from textual data and making it fit for predictive modelling. We equip to functionalities namely TFIDF & Count vectorizer. CountVectorizer is used to convert a drove of text documents to a vector of term/token counts. While, TFIDF vectorizer transforms the textual data into numbers that can be understandable for the ML model. We perform both vectorizing methods in the train and test information. The subsequently result we go are on a large range of values representing each and every text in the data. Our ML model cannot learn such large values, hence we employ fit_transform() and transform() to scale parameter of data over a certain range and to learn the mean and variance of input features of datasets. Fit method calculates mean and variance, transform uses the hateful and variance to transform the all the features in our data.Using the transform method nosotros can use the same mean and variance every bit information technology is calculated from our training information to transform our test data.
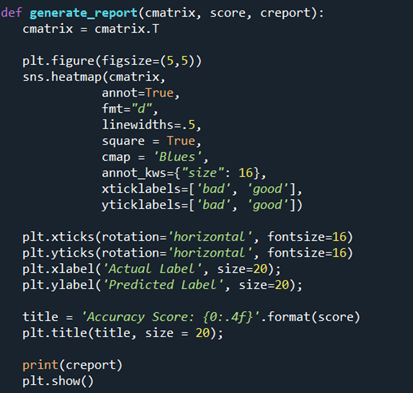
To generate the study of the performance of ML algorithm over the dataset we define a role which generates a estrus map to get confusion matrix that tells the call back and precision, gives readings nearly how many false-negatives, false positives, true negative and true positives as well. In the title nosotros have score printed i.eastward accuracy score of our model every bit i show below.
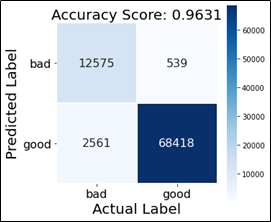
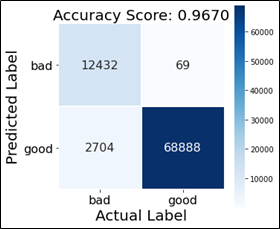
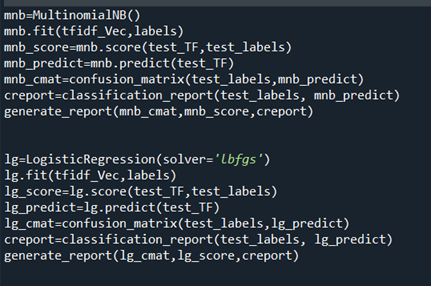
Afterward doing all the necessary pre-processing for the data, nosotros have our data ready to be fed into the ML model. We utilise Multinomial Naïve Bayes and Logistic Regression as our models to make prediction whether the url is malicious or non. We define MNB and fit into the vectorized urls as our input information and labels as the predicted output. Then nosotros generate a score that tells the accuracy of our model, and predict the urls equally whether malicious or not, followed by which we call the function 'classification_report' and generate the corresponding report. We practise the same for Logistic regression as well.
Code Conclusion
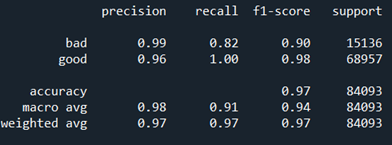
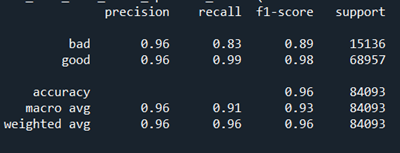
Balancing between Recall and Precision
In cases such as credit menu fraudulent detection/ tumor classification, fifty-fifty if a single example gets misclassified, information technology turns out to be a serious problem as so much coin or a life may be put in danger. Hence in such cases what we practice is we need to bring a correct balance betwixt Recall and precision. For cases similar this we need to have a high recall score equally it tells u.s. virtually how accurate our model has made prediction and classified True positives out of actual positives in the dataset. Through means of F1 Score, we tin bring balance between precision and recall.
Do hit like button if constitute interesting :)))

What Are The Risks With Machine Learning For Url Categorization,
Source: https://medium.com/analytics-vidhya/malicious-webpage-classification-using-machine-learning-607e2aecab2
Posted by: whitehavager.blogspot.com
0 Response to "What Are The Risks With Machine Learning For Url Categorization"
Post a Comment